ComfyUI+Sonic实战,三步实现图片开口说话
在 AI 多模态技术爆发的今天,如何让静态图片“开口说话”成为热门课题。Sonic模型通过图像+音频驱动数字人视频生成,在视频质量、唇部同步精度、运动多样性和时间连贯性方面显著提升。
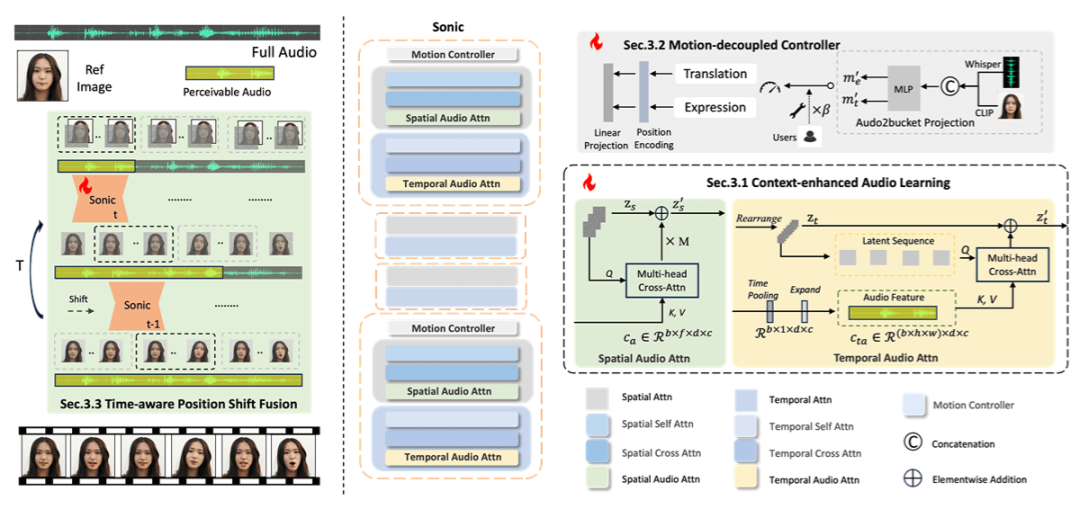
ComfyUI作为节点式工作流工具,能将这一过程简化为可视化操作。两者结合后,开发者在OneThingAI平台上只需 3 步即可实现:
1. 上传人物照片
支持正面 / 侧面高清肖像
2. 输入语音文件
支持 WAV/MP3 等格式
3. 一键生成视频
自动匹配口型与动作
环境搭建与模型准备
1. 云平台部署
登录OneThingAI控制台,选择ComfyUI官方镜像,如配置RTX 4090显卡,实测生成一分钟的视频需要20分钟左右。

2. 模型&节点
下载Sonic模型并安装到对应路径下
- 关键模型说明
unet.pth | 核心生成网络 | Sonic仓库yoloface v5m.pt | 人脸检测模型 | LeonJoe13/Sonic 仓库svd xt 1 1.safetensors | 动态视频扩散模型 | hugging face- Sonic模型地址
模型下载:https://gitcode.com/gh_mirrors/co/ComfyUI_Sonic
节点下截:https://gitcode.com/gh_mirrors/sonic5/Sonic
安装路径:/root/ComfyUI/models/
- Svd模型地址
模型下载:https://huggingface.co/vdo/stable-video-diffusion-img2vid-xt-1-1/blob/main/svd_xt_1_1.safetensors
安装路径:/root/ComfyUI/models/checkpoints/
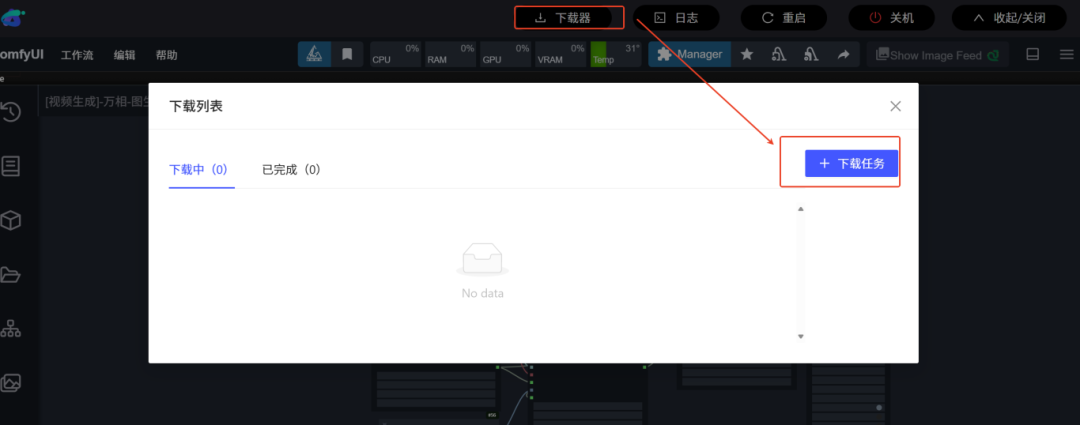
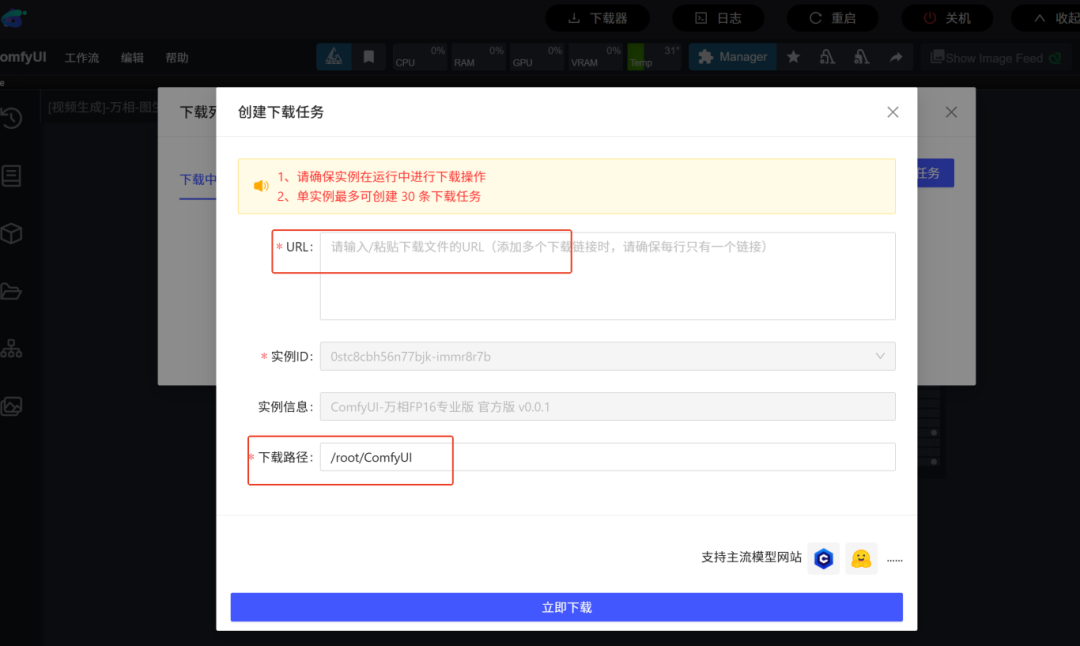
注:以上可通过ComfyUI镜像中的下载器下载,如下图所示
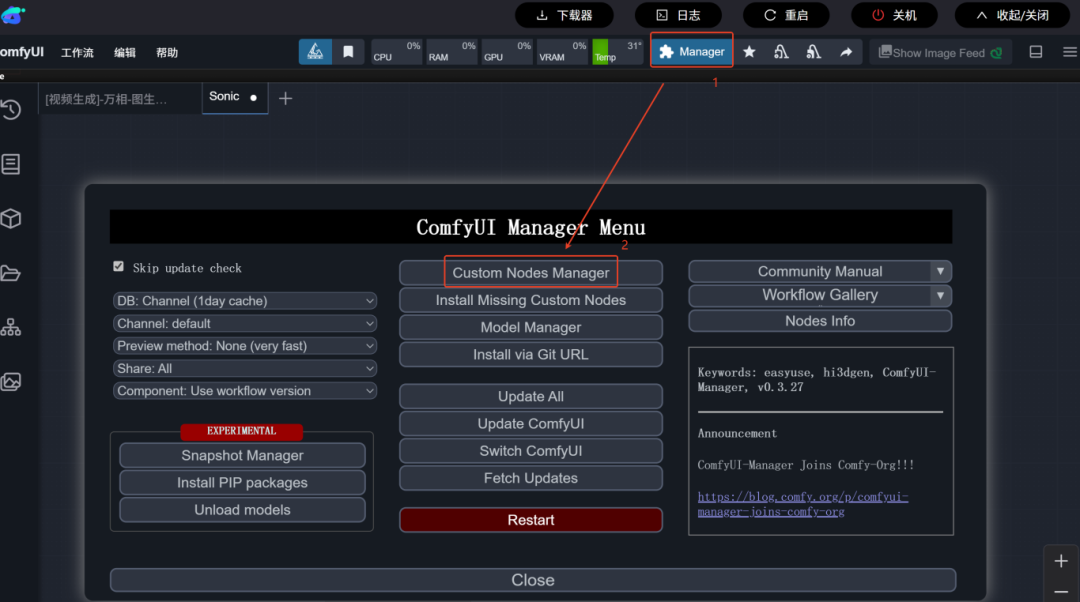
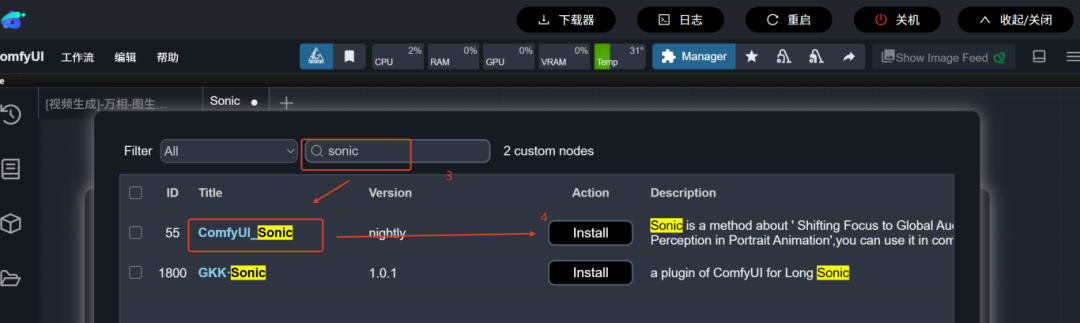
3. Sonic节点下载步骤
在ComfyUI管理器 → 节点管理 → 搜索Sonic → 下载相关节点 → 下载完成后点击【重启】实例。如下图所示

工作流搭建与参数调整
1.工作流
上传图片和音频即可生成视频。如下图所示:
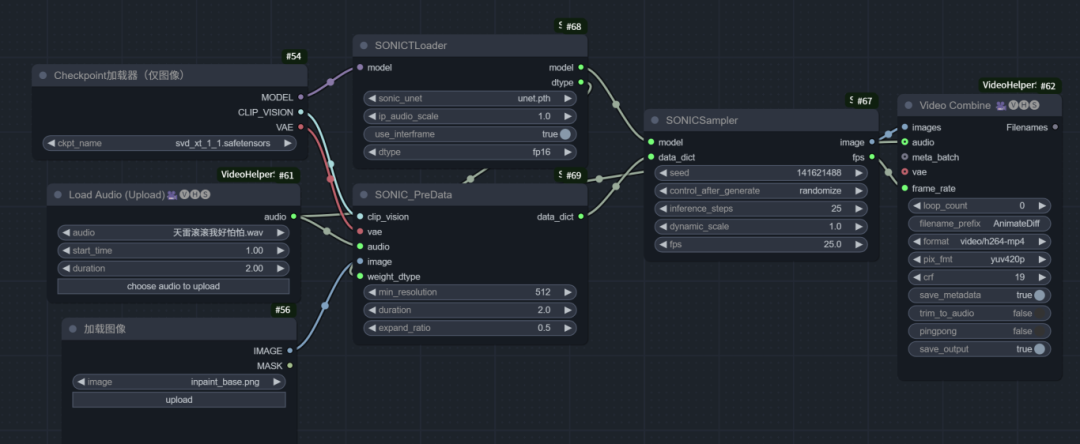
2. 关键参数详解
duration | 1-600 秒 | 控制视频总时长min resolution | 384-1024 | 调整视频最短边分辨率motion scale | 0.5-2.0 | 控制数字人动作幅度face_padding | 0-0.3 | 人脸裁剪留白比例通过ComfyUI与Sonic的结合,我们借助OneThingAI算力云平台可实现从静态图片到动态数字人的全流程自动化。